Learning to Reconstruct Multi-Modal 3D Object Representations
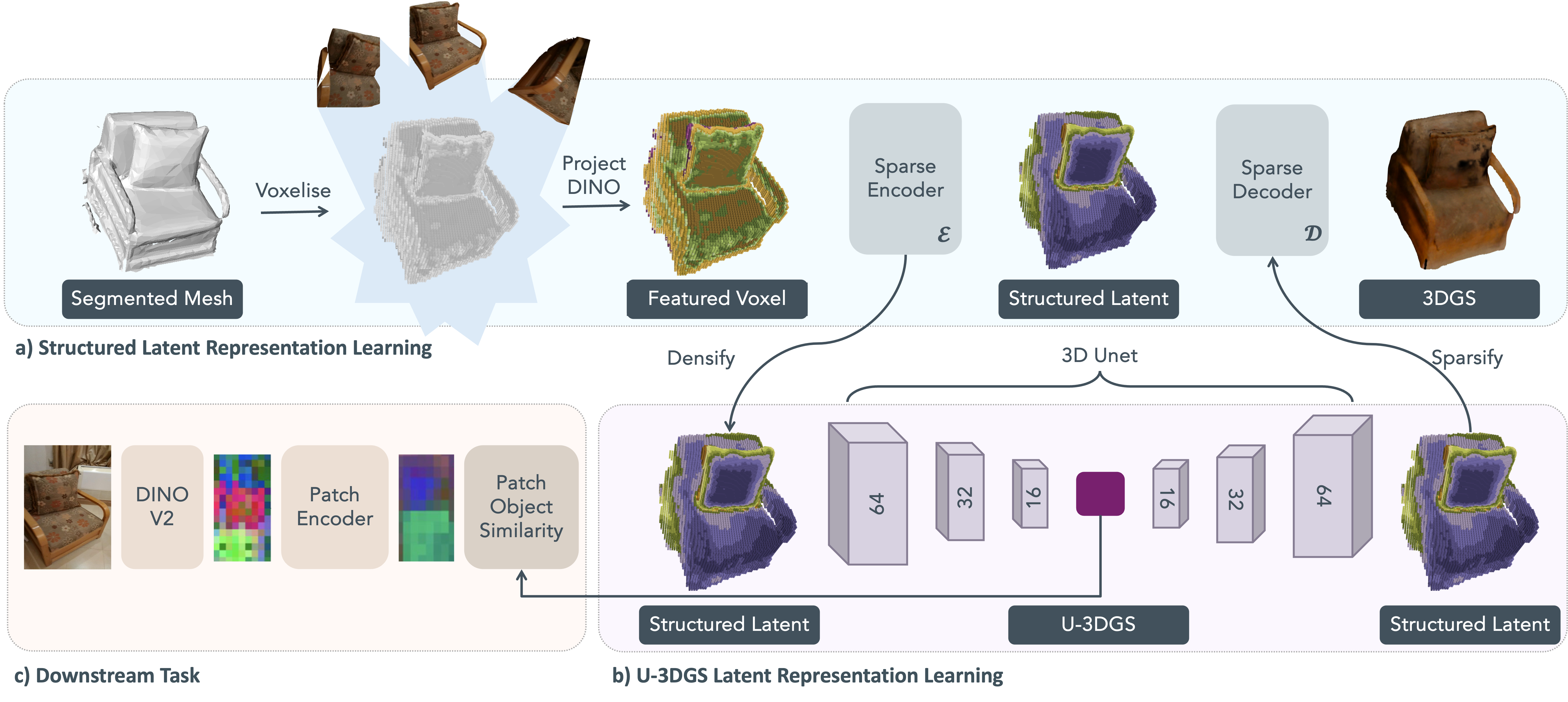
Overview of the proposed pipeline which learns object embeddings to reconstruct 3D Gaussians and support downstream tasks such as visual localization. (a) The method takes a mesh or point cloud of an object along with posed images observing it. The canonical object space is voxelized based on object geometry, and DINOv2 features extracted from the images are assigned to each voxel. This produces a 64 x 64 x 64 x 8 structured latent (SLat) representation. (b) The SLat is further compressed into a 16 x 16 x 16 x 8 U-3DGS embedding using a 3D U-Net. The embedding is trained with a masked mean squared error loss to ensure accurate reconstruction of the SLat, which in turn enables decoding into 3D Gaussians using standard photometric losses. (c) Additional task-specific losses, such as those for visual localization, can be incorporated to optimize the embedding for multiple objectives.
The proposed Object-X learns per-object embeddings that are beneficial for a number of downstream tasks, besides object-wise 3DGS reconstruction, such as cross-modal visual localization (via image-to-object matching), 3D scene aligment (via object-to-object matching), and full-scene reconstruction by integrating per-object Gaussians primitives.
We show qualitative comparison between 3DGS optimized on all images from the dataset - on the top - and Object-X - on the bottom - on few objects. We show Object-X can reconstruct the object with comparable visual quality to 3DGS, while significantly improving the geometric accuracy.
If you find our work useful, please consider citing:
@misc{dilorenzo2025objectxlearningreconstructmultimodal, title={Object-X: Learning to Reconstruct Multi-Modal 3D Object Representations}, author={Gaia Di Lorenzo and Federico Tombari and Marc Pollefeys and Daniel Barath}, year={2025}, eprint={2506.04789}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2506.04789}, }